
Как восстановить сайт из вебархива, и для чего это нужно?
Ни для кого не секрет, что далеко не у всех вебмастеров хватает «запала», чтобы вести свои проекты до победного конца. Рано или поздно, все приходит к тому, что владелец площадки буквально забрасывает ее, и смещает свой спектр внимания на какую-то другую деятельность. А задумывались ли вы когда-то о том, куда пропадают эти самые заброшенные сайты?

Де-факто, процесс довольно прозаичен. Забили на сайт – перестали оплачивать домен – доступ к сайту пропал. Ну и на самом хостинге рано или поздно все файлы почистят, если вебмастер его не оплачивает. Тем не менее, все вы знаете фразу, что «интернет помнит все». И в данном случае это правило работает именно так.
Что такое вебархив, и зачем из него что-то доставать?
Web Archive – это, если позволите, своеобразная машина времени. Она может вернуть вас к тем веб-сайтам, которые перестали существовать еще десятки лет назад. Только представьте, сколько интересных перлов можно отыскать. Целое поле для исследовательской деятельности. Впрочем, куда важнее экономический, практический аспекты.
Почему в принципе кто-то интересуется веб-архивами? Причина в том, что «все новое – это хорошо забытое старое». Web Archive содержит массу ресурсов, которые содержат и уникальные изображение, и различные тексты, которые уже давно не индексируются, а следовательно – обладают высокой уникальностью, и их вполне можно использовать для своих целей.
И, если сейчас вы задумались над тем, что не может все быть настолько просто – вы абсолютно правы. Но причина тут не в том, что достать определенные файлы из веб-архива как-то проблематично. Напротив, это крайне просто, и мы еще поговорим об этом. Дело, скорее, в высоком уровне конкуренции. Ведь кто же не любит халявы? Предприимчивые вебмастеры уже давно вытаскивают из веб-архивов все самое «вкусное», и успешно монетизируют уже забытый контент.
Да, откровенно устаревшая информация будет вряд ли полезной для какого-нибудь СДЛ. Разве что кроме тех случаев, когда дело касается какой-то ниши, а-ля медицина. Ведь ОРВИ – он и десять лет назад был ОРВИ. Ничего нового в этом плане и не придумаешь.
Но куда чаще статьи из веб-архивов берут для ГС. Покупается какой-то домен, которому уже лет 10, ищут уникальные статьи в веб-архивах, заливают, добавляют сайт в биржи ссылок (GoGetLinks, Miralinks, и другие), и готово. При минимальных вложениях получается отличный бизнесактив.
Как получить данные из веб-архива?
Учитывая то, что веб-архив чем-то напоминает традиционную библиотеку, вовсе не удивительно, что уже давно существует платформа, где вся информация структурирована, и вы буквально можете проследить историю того или иного веб-сайта. Тут, скорее, больше аналогий можно провести даже с музеем. Но владельцы платформы назвали его, практически, машиной времени — Wayback Machine. На данный момент, проект собрал около 280 миллиардов страниц, сто действительно поражает.
И прежде, чем вы воспользуетесь веб-архивом, необходимо найти себе цель для восстановления. То есть, вам нужно знать тематику сайта, найти домен, и уже по нему проводить поиски.
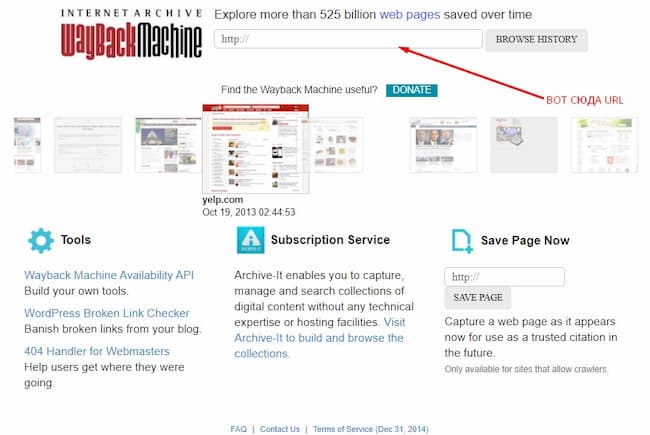
Далее – переходим на сервис, ссылку на который мы оставили выше, на Wayback Machine. Пишем URL-сайта. Это может быть не только уже «мертвый» ресурс, неизвестный вам. Вы вполне можете попытаться восстановить и ваш собственный сайт, на который вы в свое время «забили». Вписываем адрес в соответствующую строку.
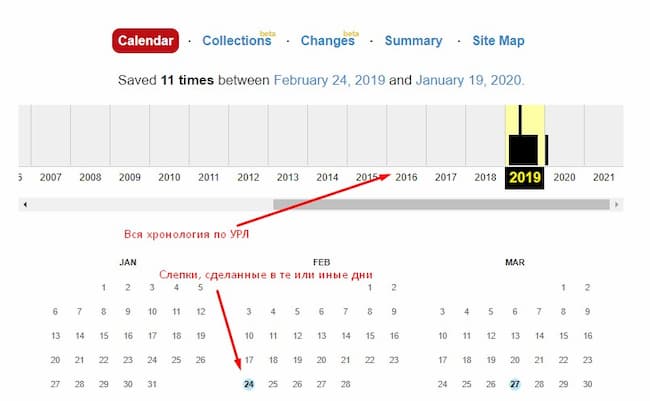
Вбив в строку адрес веб-сайт, откроется строка с хронологией. В ней вы сможете выбрать конкретный год, информацию за который вы ищите. Ниже расположены календари, где синими кругами отмечены те даты, когда был создан слепок веб-сайта.
И дальше все просто: жмем на дату – открывается слепок. Качество его может быть разным. Где-то могут отсутствовать куски информации. В других случаях, можно достать даже изображения. Тут уж как повезет. Но, как показывает практика, все тексты будут без изменений (иногда страдает лишь форматирование). И вы вполне можете использовать их в своих целях, не забывая предварительно пропускать их через сервисы по проверке уникальности.
Как восстановить сайт из веб-архива?
Самый очевидный способ восстановить веб-сайт, найденный в веб-архиве – проделать всю работу руками. В таком случае, потребуется пусть и много времени, но если вы продумали какой-то определенный план, то, вероятно, затраченное время себя окупит.
Тем не менее, есть способ автоматизировать процесс. Для этого необходимо установить, к примеру, язык программирования Ruby, с его помощью установить программу для скачки сайтов из Wayback Machine (для этого в компиляторе достаточно ввести команду gem install wayback_machine_downloader). И далее – задаем команду для скачивания слепка в таком формате: wayback_machine_downloader http://www.имясайта.ru -timestamp 20201207110704. В конце, как вы понимаете, мы задаем конкретный слепок, указывая дату.
Разместить файлы в определенном месте поможет утилита rsync. Дальше заливаем все на сервер, и «играемся» с полученной копией: достаем нужную инфу, или же вовсе доводим до работоспособного состояния.






 (4 оценок, среднее: 3,00 из 5)
(4 оценок, среднее: 3,00 из 5)
